1. Introduction
언어모델(Pretrained-language model)들의 파라미터가 기하급수적으로 늘어나면서 전체 파라미터를 파인튜닝시키는 것이 자원적으로 많은 부담이 되고 있습니다. 이러한 문제점을 보완하기 위해 사전학습 모델의 파라미터는 학습을 시키지 않고(freeze) 모델에 새로운 레이어를 추가하고 그 레이어만 학습하는 방식이 연구되고 있습니다. 대표적으로 LSTM구조의 prompt encoder를 붙인 p-tuning과 이번에 소개할 LoRA(Low-Rank Adaptation)가 있겠습니다. LoRA는 레이어 중간중간에 low-rank matrice들을 삽입함으로써 파라미터를 효율적으로 학습하는 방법을 제안했습니다.

그림과 같이 파란색 부분은 학습시키지 않고 $A(r*k)$ 와 $B(d*r)$를 학습시켜 기존 파라미터에 합치는 형식으로 학습시간을 매우 단축시켜 주고 간단한 선형 레이어이기 때문에 inference latency 또한 없습니다.
2. Method
기존 파인튜닝은 데이터 쌍 x, y에 대해 Φ0 + ∆Φ로 업데이트 하는 것입니다.

LoRA에서는 기존 파라미터 대비 훨씬 적은 파라미터 $\theta$를 업데이트합니다.

위 그림을 통해 forward pass를 식으로 표현하면 다음과 같습니다.

- $W_0$는 freeze
- A는 가우시안 초기화 (코드에서는 kaming_uniform초기화)
- B는 0으로 초기화
다른 task로 전환 시 BA를 뺐다 더했다 하기만 하면 되기 때문에 inference에 추가적인 비용이 들지 않습니다.
3. Experiment

GPT-3 전체 파라미터를 파인튜닝 한 것보다 LoRA로 학습시킨 것이 성능이 좋게 나왔습니다.
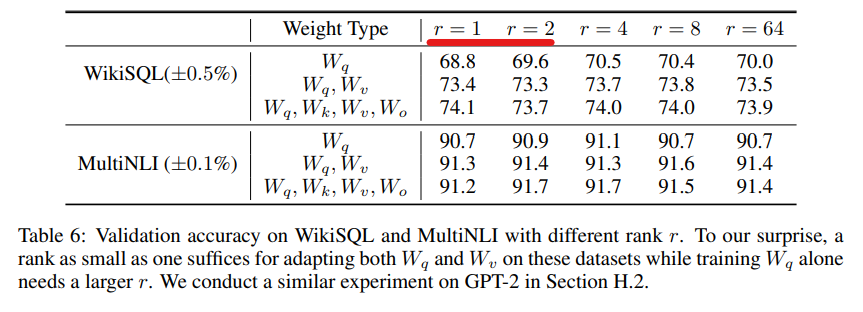
작은 rank에서도 동작하는 것을 볼 수 있습니다. GPT-3 175B의 경우 전체 파라미터의 rank가 12888 정도 되는데 이걸 1~2로 학습을 해도 성능이 잘 나온다는 것은 컴퓨팅 자원의 효율을 많이 아낄 수 있음을 의미합니다.
4. Code
코드는 간단합니다. 선형 레이어들을 loralib 이용하여 바꿔주기만 하면 됩니다.
1-1. replace linear layer
# ===== Before =====
layer = nn.Linear(in_features, out_features)
# ===== After ======
import loralib as lora
layer = lora.Linear(in_features, out_features, r=2)1-2. train
import loralib as lora
model = BigModel()
# This sets requires_grad to False for all parameters without the string "lora_" in their names
lora.mark_only_lora_as_trainable(model)
# Training loop
for batch in dataloader:
...1-3. save model
# ===== Before =====
torch.save(model.state_dict(), checkpoint_path)
# ===== After =====
torch.save(lora.lora_state_dict(model), checkpoint_path)
라이브러리 코드를 자세히 보면 다음과 같이 이루어져 있습니다.
2-1. init부분에서 if r > 0: 부분을 보시면 두 개의 행렬 A, B를 만듭니다.
2-2. train에서 파라미터(weight)에서 BA를 빼주는 부분은 새로운 task로 학습 시 원래의 파라미터로 복원해 줄 수 있게 합니다.(위에서 말한 뺏다 더했다)
2-3. eval에서 새롭게 학습한 파라미터를 기존에 학습된 파라미터에 합치기만 하면 되기 때문에 추가적인 연산이 필요하지 않게 되어 inference latency가 없게 됩니다.
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
if self.r > 0:
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)https://arxiv.org/pdf/2106.09685.pdf
https://github.com/microsoft/LoRA/tree/main
GitHub - microsoft/LoRA: Code for loralib, an implementation of "LoRA: Low-Rank Adaptation of Large Language Models"
Code for loralib, an implementation of "LoRA: Low-Rank Adaptation of Large Language Models" - GitHub - microsoft/LoRA: Code for loralib, an implementation of "LoRA: Low-Rank Adaptati...
github.com
'AI/ML > NLP' 카테고리의 다른 글
| [NLP] Something of Thoughts 프롬프트 테크닉 (CoT, ToT) (0) | 2023.12.10 |
|---|---|
| [Paper Review] 생성 AI로 만들어졌는지 판단하기 (DetectGPT) (1) | 2023.11.26 |
| [Paper Review] Don’t Stop Pretraining (0) | 2022.10.23 |
| [Review] OpenAI의 DALL-E2 공개 (0) | 2022.04.24 |
| [Paper Review] RoBERTa: A Robustly Optimized BERT Pretraining Approach (0) | 2022.03.13 |