
최근 나온 생성 모델들을 추천시스템에도 활용할 수 있지 않을까 생각하던 중 A Survey on Large Language Models for Recommendation 이 논문에서 지금까지 나왔던 언어모델들을 추천시스템에 적용한 연구들을 잘 정리해 두어 이를 참고하여 어떻게 적용했는지 정리해보려고 합니다.
1. 추천시스템을 위한 언어모델

추천을 위한 언어모델은 크게 2가지로 분류할 수 있습니다. Discriminative LLM은 BERT와 같은 사전훈련된 언어모델을 파인튜닝하여 사용합니다. 유저-아이템 행동정보를 입력으로 받아 상품을 추천하는 방식이고 관련 연구도 많고 성능도 괜찮게 나오는 편입니다. 하지만 제가 요새 관심을 가지는 것은 Generative LLM쪽입니다. 적절한 프롬프트를 활용해서 파라미터를 튜닝하거나 튜닝하지 않고도 자연어를 생성하여 추천에 사용하는 방식입니다. 그중 TALLRec과 M6에 대해 알아보겠습니다.
2. TALLRec ( Tuning framework for Aligning LLMs with Recommendations)
TALLRec에서는 instruct-tuning, rec-tuning 두 단계로 모델을 학습합니다. instruct-tuning단계에서는 Alpaca 학습에 사용한 instruct 데이터를 통해 LLM의 일반화 능력을 향상시키고, rec-tuning에서는 유저의 기록을 바탕으로 생성한 instruct 데이터를 통해 학습합니다. instruct데이터의 예시는 다음과 같습니다.
유저 선호 : 상품 A, 상품 D, 상품 E
유저 비선호 : 상품 C, 상품 F
이 유저는 상품 G를 선호 할 것인가? [예/아니오]
예2-1. 성능
기존 시계열 모델 (GRU, BERT) 보다 더 나은 성능을 보여주고
ChatGPT보다도 성능이 더 좋게 나온다고 합니다.
3. M6-Rec
M6는 알리바바에서 수행한 연구로 추천시스템의 다양한 task를 풀기 위한 베이스라인 모델을 완전한 자연어 프롬프트로 학습시켰습니다. 생성뿐만 아니라 scoring(CTR,CVR predict), explanation 등의 다양한 task에 활용가능합니다.

보시면 유저의 행동을 완전히 자연어로 바꾼것을 볼 수 있습니다. "12월 중국 베이징 추운 날씨. 이 남자는 23분 전 '겨울 용품'을 검색했고 19분 전 "경량 후드 자켓"이라는 이름의 카테고리는 "자켓"인 제품을 클릭했다..." 이렇게 말이죠. 또한 generation task에서 'The user likes it because'를 통해 추천에 대한 이유도 알 수 있는 일종의 XAI도 가능합니다.
[BOS′] 와 [EOS′]로 사이에 유저의 행동 데이터(user feature)가 들어가고
[BOS] 와 [EOS] 로 사이에 상품, 상품-유저 인터렉션 데이터(candidate feature)가 들어가게 됩니다.
3-1. 성능
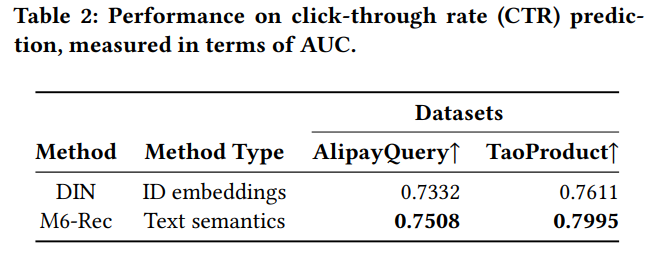
CTR 예측에서 DIN(Deep Interest Network)보다 성능이 좋고
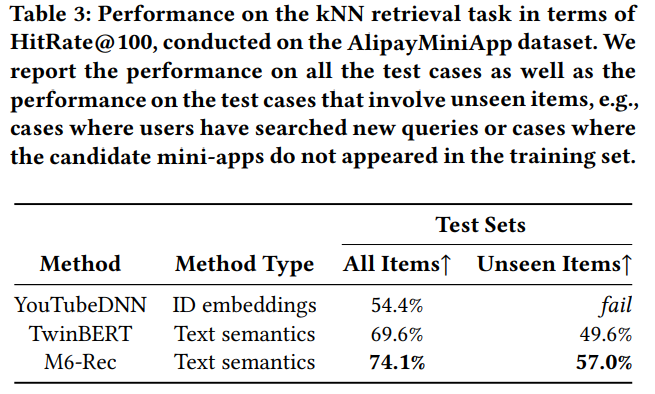
AlipayMiniApp 데이터셋에 대한 knn retrieval task에서도 성능이 잘 나온다고 합니다.
https://arxiv.org/pdf/2305.00447.pdf
https://arxiv.org/pdf/2205.08084.pdf
'AI/ML' 카테고리의 다른 글
| [Paper Review] Dropout: A Simple Way to Prevent Neural Networks fromOverfitting (0) | 2023.01.29 |
|---|