1. 동기? 비동기?
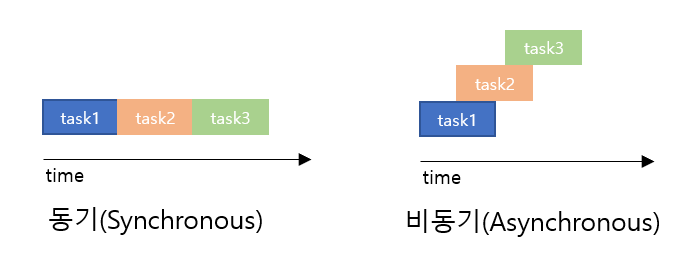
동기 프로그래밍 : 동기 프로그래밍은 작업들이 순차적으로 실행되며, 하나의 작업이 끝나야 다음 작업이 시작됩니다. 이것은 작업들 간의 의존성이 높고, 순서가 중요한 경우에 주로 사용됩니다.
비동기 프로그래밍 : 비동기 프로그래밍은 작업들이 동시에 진행되며, 하나의 작업이 완료될 때까지 다른 작업을 차단하지 않습니다.
빅데이터에서는 코드에 필요한 데이터를 얻어오는 작업에 병목이 생길 수 있습니다. 이런 I/O bound 위주의 프로그램에서는 I/O 효율을 비동기적으로 개선함으로써 실행속도를 빠르게 할 수 있습니다.
네이버에서 300개 기업의 재무제표를 크롤링하는 경우를 예로 보겠습니다.
2. 동기 프로그래밍
from pykrx import stock
import pandas as pd
import requests
import time
def crawling():
kospi_list = stock.get_market_ticker_list(market="KOSPI")[:300]
for stock_code in kospi_list:
# 네이버 파이낸스 재무재표 URL
url = f"https://navercomp.wisereport.co.kr/v2/company/c1010001.aspx?cmp_cd={stock_code}&finGubun=MAIN&frq=0&rpt=0"
# HTTP GET 요청을 보내고 페이지 내용을 가져옵니다.
response = requests.get(url)
if response.status_code == 200:
dfs = pd.read_html(response.text)
if len(dfs) >= 3:
financial_statement = dfs[5]
# 출력
print(financial_statement)
else:
print("데이터프레임이 부족합니다.")
else:
print("페이지를 가져올 수 없습니다.")
if __name__ == "__main__":
start = time.time()
crawling()
end = time.time()
print(f"elapsed time = {end - start}s")
$ elapsed time = 38.32848024368286s
위 코드를 실행하면 다음과 같은 결과가 나오며 총 38초가량 걸렸습니다. 이제 이 코드를 비동기로 바꿔보겠습니다.
3. 비동기 프로그래밍
from pykrx import stock
import pandas as pd
import time
import aiohttp
import asyncio
async def fetch_data(stock_code):
url = f"https://navercomp.wisereport.co.kr/v2/company/c1010001.aspx?cmp_cd={stock_code}&finGubun=MAIN&frq=0&rpt=0"
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
if response.status == 200:
response_text = await response.text()
dfs = pd.read_html(response_text)
if len(dfs) >= 3:
financial_statement = dfs[5]
# 출력
print(f"Financial Statement for {stock_code}:")
print(financial_statement)
else:
print(f"데이터프레임이 부족합니다. ({stock_code})")
else:
print(f"페이지를 가져올 수 없습니다. ({stock_code})")
async def main():
kospi_list = stock.get_market_ticker_list(market="KOSPI")[:300]
# asyncio.gather()를 사용하여 여러 개의 fetch_data() 함수를 병렬로 실행
tasks = [fetch_data(stock_code) for stock_code in kospi_list]
await asyncio.gather(*tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
start = time.time()
loop.run_until_complete(main())
end = time.time()
print(f"elapsed time = {end - start}s")
loop.close()
$ elapsed time = 9.29116439819336s
총 9초가량 걸렸습니다. 주요 코드에 대해 설명하자면
1. 함수를 비동기 함수로 정의하는 부분입니다.
async def fetch_data(stock_code):
2. aiohttp의 ClientSession()을 사용하여 HTTP 요청을 보내기 위한 세션을 생성합니다. 세션은 여러 요청을 관리하는 데 사용됩니다. 또한 세션을 사용하여 지정된 URL에 HTTP GET 요청을 보냅니다. 응답을 받기 위해 async with 문을 사용합니다.
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
3. 응답을 텍스트로 읽습니다. await을 사용하여 비동기적으로 응답을 받습니다.
response_text = await response.text()
4. main() 함수를 정의합니다. 이 함수는 fetch_data() 함수를 비동기적으로 호출합니다.
async def main():
5. fetch_data() 함수를 호출할 각 종목 코드에 대한 작업 목록(tasks)을 생성합니다. asyncio.gather() 를 사용하여 모든 작업을 비동기로 실행합니다.
tasks = [fetch_data(stock_code) for stock_code in kospi_list]
await asyncio.gather(*tasks)
6. asyncio 이벤트 루프를 생성하고, main() 함수를 비동기적으로 실행합니다. 코드가 실행되면 병렬로 여러 종목의 재무제표 데이터를 크롤링하고 출력합니다.
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
4. 결론
asyncio를 사용하여 비동기 프로그래밍으로 속도를 개선해 봤습니다. 제대로 배우려면 코루틴(coroutine), 재너레이터에 대해 배워야 하지만 일단 이런 것이 있다 정도만 알아두면 유용할 것 같습니다. 또한 여기서 multiprocessing 같은 모듈을 사용하면 더욱 속도를 줄일 수 있습니다. 하지만 간단한 크롤링의 경우에는 비동기로 충분한 것 같습니다.
'Python' 카테고리의 다른 글
| [Python] 컴파일로 속도 개선하기(Cython) (0) | 2023.10.31 |
|---|---|
| [Python] 프로파일링으로 병목 찾기 (line_profiler) (1) | 2023.10.09 |
| [Python] 언어모델의 출력을 스트리밍 방식으로 출력하기 (1) | 2023.06.11 |
| [Python] PEFT 라이브러리 알아보기 (0) | 2023.05.29 |
| [Python] Folium으로 지도에 행정구역 경계 표시하기 (0) | 2023.02.26 |