
- shape 변경(view,reshape,transpose,permute)
- 차원 추가,삭제(squeeze,unsqueeze)
- Tensor 병합(stack,cat(concat)
- repeat,expand
- scatter,gather
view() vs reshape()
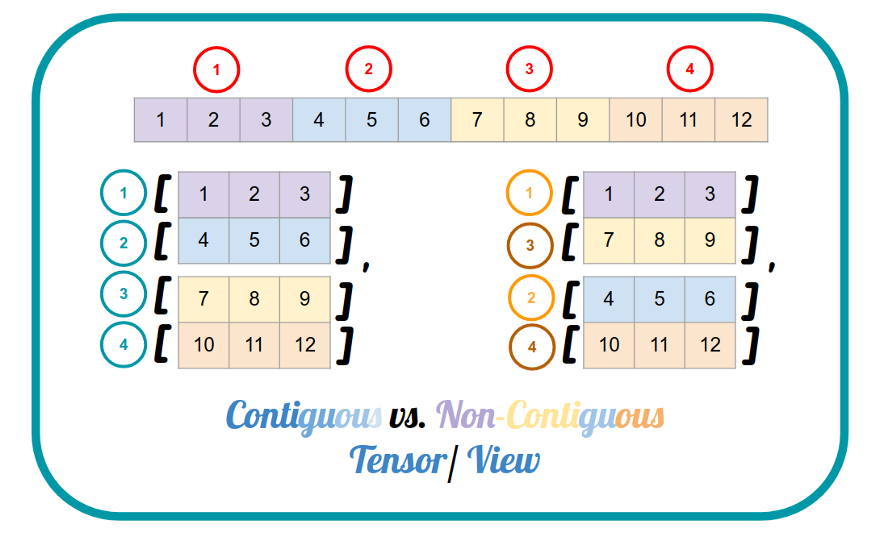
※ 우선 contiguous에 대해 알아야 하는데, data의 메모리상 물리적 위치 주소와 tensor내 data의 index 순서가 일치하면 contiguous 하다고 한다.
view : contiguous tensor에만 실행 가능하며 contiguous tensor 반환, 원본의 data가 바뀌면 view로 반환된 tensor도 바뀐다. -> contiguous 보장
reshape : contiguous tensor에서는 view와 동일하며 non-contiguous tensor에서는 data를 복사, 따라서 non-contiguous tensor의 경우 원본의 data가 바뀌어도 reshape으로 반환된 tensor는 바뀌지 않는다. -> non-contiguous해도 reshape 후 강제로 contiguous 보장
a=torch.tensor([[0,0,0],
[0,0,0]])
a.shape #(2,3)
reshape=a.T.reshape(6)
reshape.shape #(6)
a.fill_(1)
위에서 transpose로 non-contiguous 하게 만든 후 reshape을 하면 원본의 data가 바뀌어도 반환된 tensor에 영향을 주지 않는다.
transpose()
transpose()는 두 개의 차원만 교환한다.
permute()
permute()는 모든 차원들을 교환할 수 있다.
view() vs permute()
view의 경우 contiguous를 유지하기 위해 data의 순서를 지킨다. 반면에 permute는 transpose연산이 진행된다.

squeeze, unsqeeze
squeeze : 차원의 size가 1인 차원을 제거해준다. 따로 차원을 설정하지 않으면 1인 차원을 모두 제거하며 차원을 설정해주면 그 차원만 제거한다.
a=torch.rand(3,1,5,1)
b=a.squeeze() #(3,1,5,1) -> (3,5)
c=a.squeeze(3) #(3,1,5,1) ->(3,1,5)unsqueeze : squeeze함수의 반대로 size가 1인 차원을 생성하는 함수이다. 그래서 어느 차원에 1인 차원을 생성할지 지정해주어야 한다.
a=torch.rand(3,5)
b=a.unsqueeze(1) # (3,1,5)
c=a.unsqueeze(2) # (3,5,1)stack , cat(concat)
stack : 지정한 차원에 새로운 차원을 만들어 tensor를 쌓는다. 두 tensor를 쌓기 위해서 tensor의 차원이 일치해야 한다.

지정한 차원(dim=3)에 새로운 차원이 생기며 shape이 같은 두 tensor를 쌓는다.
cat : 차원의 수는 유지한 채 concat 하고자 하는 차원으로 tensor를 이어 붙인다.

concat 하고자 하는 차원(dim=2)으로 두 tensor를 이어 붙인다.
repeat, expand
repeat : 지정한 size만큼 tensor를 반복한다.

expand : tensor를 지정한 size로 만든다. 크기가 1인 차원에만 적용할 수 있다.

scatter, gather
scatter : Tensor.scatter_(dim, index, src, reduce=None) , dim방향으로 src로부터 해당하는 index에 있는 값을 가져온다. 말로만 들으면 매우 어렵다.


input은 0으로 이루어져 있고 src로부터 값을 채운다고 생각하면 쉽다.
dim이 0이니까 input에는 세로 방향으로 채워지고
src에 1에 해당하는 index는 0이니 input에 [0,0]에 1이 들어간다.
src에 6에 해당하는 index는 2이니 input에 [2,0]에 6가 들어간다.

마찬가지로
src에 2에 해당하는 index는 1이니 input에 [1,1]에 2가 들어간다.
src에 7에 해당하는 index는 0이니 input에 [0,1]에 7이 들어간다.

gather : torch.gather(input, dim, index, *, sparse_grad=False, out=None), index에 해당하는 값만 추출할 때 사용한다.
다음과 같이 tensor에서 대각선에 해당하는 data만 얻고 싶을 때 사용할 수 있다.

'Pytorch' 카테고리의 다른 글
| [Pytorch] DataParallel vs DIstributedDataParallel (0) | 2022.07.17 |
|---|---|
| [Pytorch] 다양한 Learning Rate Scheduler (0) | 2022.06.26 |
| [Pytorch] Onnx로 모델 export하기 (0) | 2022.06.12 |