1. Abstract
자연어 처리에서 어떤 토크나이저를 사용하냐에 따라 모델의 성능에 영향을 미칩니다. 토큰은 문맥에 대한 정보를 담고 있는 최소한의 단위이고 어떻게 토큰화를 하냐에 따라 모델의 문맥에 대한 이해가 달라지기 때문입니다. 그중 BPE(Byte Pair Encoding)이 간편함 때문에 대표적으로 사용되었지만 그 효과가 한글에도 적용될지는 의문이 있었습니다. 해당 논문은 한국어 처리 시 어떤 토크나이저가 좋은 성능을 보이는지 실험을 했으며 그 결과 Morpheme(형태소)과 BPE를 결합한 Morpheme-aware Subword 방식이 가장 놓은 성능을 보임을 밝혔습니다.
2. Introduction
Tokenization은 자연어처리의 가장 첫 단계이며 BPE가 tokenization technique 중 표준(de facto)로 여겨졌습니다. 그 이유는 data-driven statistical algorithm이기 때문이라고 합니다. 하지만 BPE가 개별 task, 모든 language에 대해서도 잘 작동할 것이라는 것에 대해서는 불투명합니다. 따라서 이 논문에서는 형태학적으로 더 풍부한 한글에 대해 Korea to English, English to Korea, NLU, MRC, NLI, STS, 감정분석 등과 같은 task에서 어떤 tokenization이 좋은 성능을 보이는지 실험을 했습니다.
3. Tokenization Strategies

CV (Consonant and Vowel)
자모 단위로 tokenization. 공백은 *로 대체
Syllable
음절 단위로 tokenization. 공백은 *로 대체
Morpheme
MeCab-ko를 사용해 형태소 단위로 tokenization. 이 경우에 공백에 제거되어 원본 텍스트로 복원이 불가능. 따라서 공백을 *로 대체
Subword
SentencePiece를 사용하여 BPE를 적용. text를 subword 단위로 tokenization. 공백 또는 첫 토큰에는 _사용
Morpheme-aware Subword
MeCab-ko와 BPE를 순서대로 적용. 형태소로 분리한 뒤 BPE를 적용하기 때문에 위 Subword 예시에서 /핑하/와 같이 묶이는 일이 없어짐
Word
단어(띄어쓰기) 단위로 tokenization
4. Experiments
Korean to/from English Machine Translation
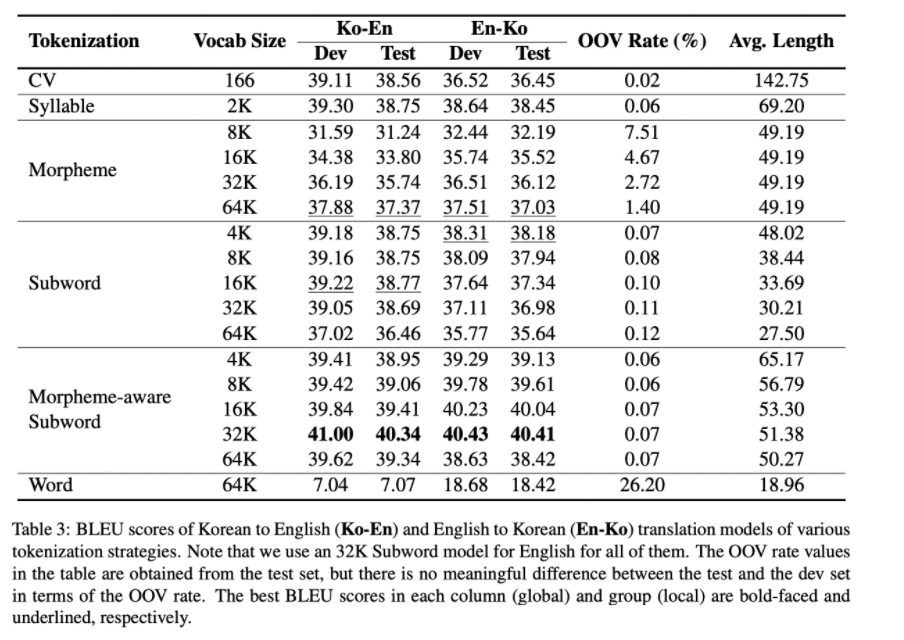
Subword, Syllable이 Morpheme(형태소)보다 좋은 성능을 보이며 낮은 OOV(out of vocabulary) rate를 보입니다. 이는 한국어는 형태소가 복잡하기 때문에 64K의 vocab size로는 OOV가 많이 발생할 수밖에 없기 때문입니다. 하지만 CV처럼 낮은 OOV를 보인다 해도 자모 단위는 문맥에 대한 정보가 부족하기 때문에 성능이 낮습니다.
NLI, MRC, STS, Sentiment Analysis, Paraphrase Identification

vocab size 64K의 Morpheme-aware subword가 MRC(KorQuAD)를 제외하고 가장 성능이 좋습니다. vocab size와 성능이 비례할 것 같았으나 STS(Semantic Textual Similarity) Task에서 32K가 성능이 가장 높은 것으로 보아 vocab size와 성능은 비례하지 않습니다.
5. Discussion
Token Length

token length가 성능에 미치는 영향을 알아봅니다. Token length는 한 token에 포함된 Syllable(음절) 수의 평균을 말합니다. Morpheme은 형태소 단위로 tokenize를 하기 때문에 vocab size가 커져도 token length가 일정합니다. Subword와 Morpheme-aware-Subword는 BPE를 사용하기 때문에 vocab size가 커짐에 따라 token length도 증가하게 됩니다. 묶이는 token들이 많아지기 때문입니다. Token length가 1.5인 부분에서 성능이 장 좋으면 1.5를 넘어가기 시작하면서 성능이 감소합니다.
Linguistic
위 Figure 1에서 8K Subword와 16K Morpheme-aware Subword는 token length가 동일하지만 형태소로 먼저 나눈 Morpheme-aware Subword가 더 좋은 성능을 보여주는 것은 token length뿐만 아니라 언어에 대한 이해(linguistic awareness)도 중요하다는 것을 보여줍니다.
Under-trained Tokens

Morpheme의 낮은 성능이 높은 OOV rates때문이라고 지적합니다. 이는 Morpheme이 under-trained된 token이 많다는 것을 의미합니다.
참고
'AI/ML > NLP' 카테고리의 다른 글
| [Paper Review] LoRA: Low-Rank Adaptation of Large Language Models (1) | 2023.05.14 |
|---|---|
| [Paper Review] Don’t Stop Pretraining (0) | 2022.10.23 |
| [Review] OpenAI의 DALL-E2 공개 (0) | 2022.04.24 |
| [Paper Review] RoBERTa: A Robustly Optimized BERT Pretraining Approach (0) | 2022.03.13 |
| [Paper Review] Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems (TRADE) (0) | 2021.05.10 |